.png)


It’s one thing to know your perimeter is vulnerable. It’s another to know where, how, and why. That’s the challenge exposure management is built to solve. As enterprise environments become more fragmented and threats more precise, security teams are shifting their approach, from reactively patching CVEs to proactively managing exposures in context.
As of 2025, the exposure management market has grown to $8.83 billion, up from $6.72 billion in 2023, a nearly 32% increase in just two years. At this pace, it's expected to surpass $10.11 billion by 2026, compounding at an annual rate of 14.6%.
That kind of sustained growth reflects how quickly organizations are moving from fragmented detection to integrated, outcome-driven security. It’s no longer about how many vulnerabilities you can list but whether you can prove the risky ones are resolved.
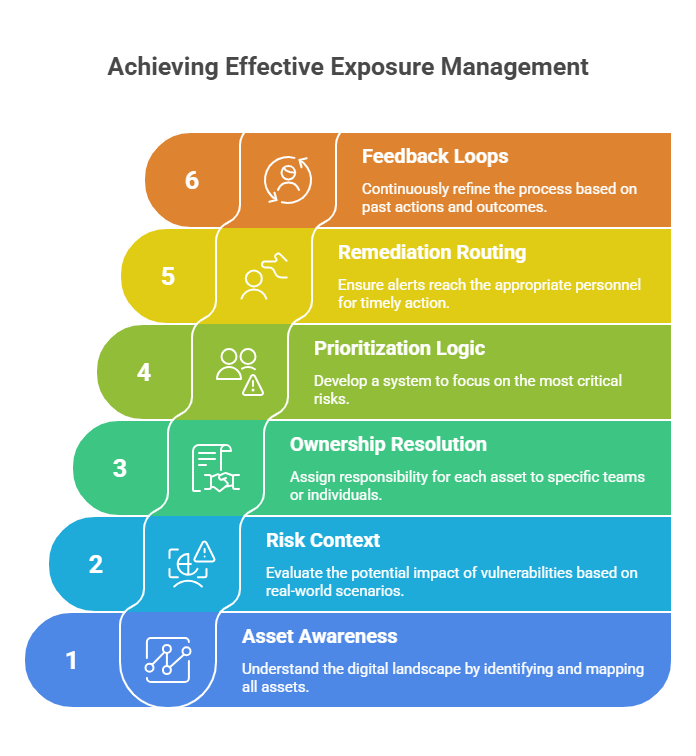
Six Core Capabilities for Effective Exposure Management
What Is Exposure Management?
Exposure management is the continuous process of identifying, prioritizing, and reducing cyber risks that are actively exploitable in your environment. It goes beyond simply detecting vulnerabilities. Instead, it focuses on which vulnerabilities truly matter based on real-world context. To manage exposure, security teams need six tightly integrated capabilities:
- Asset awareness: Know what exists, where it lives, and how it behaves.
- Risk context: Determine if something is internet-facing, actively exploited (EPSS), or critical for lateral movement.
- Ownership resolution: Know who’s responsible, down to the repo or team.
- Prioritization logic: Surface the signal in the noise, tuned to your environment.
- Remediation routing: Deliver the right alert to the right person, in the right system.
- Feedback loops: Capture actions taken, or not, and continuously refine the signal to improve accuracy.
The core problem in exposure management is fragmentation. Scanner outputs are live in one system, asset inventories are maintained in another, and remediation flows are tracked in a third.
Why the Traditional Approach Fails
The traditional vulnerability management model is fundamentally broken. It generates volume, not clarity, and leaves most teams without a clear path from detection to resolution. Some organizations are evolving by implementing continuous penetration testing methodologies to simulate real-world attack paths and surface true exploitable exposures.
Security teams are inundated with thousands of findings, most of which are irrelevant and many of which are unactionable. Instead of surfacing relevant exposures, scanners dump data into triage queues, wasting cycles on noise that should never have reached the backlog.
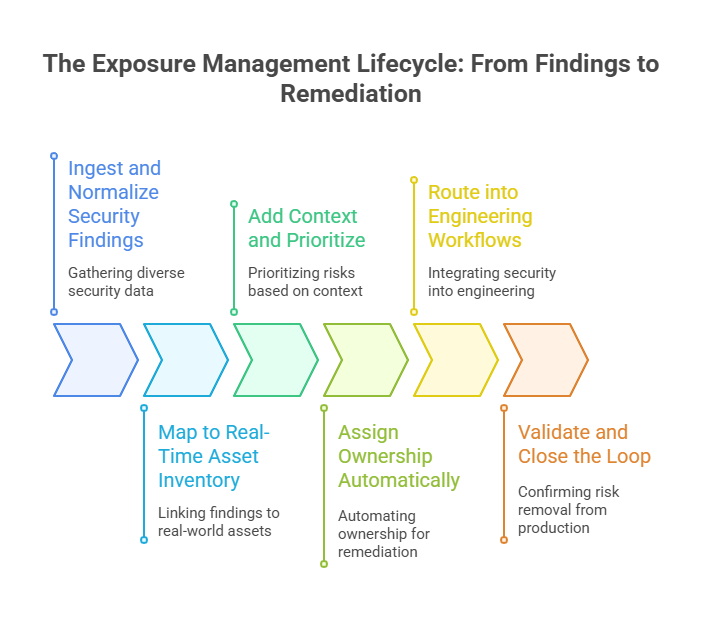
The Exposure Management Lifecycle
When done well, exposure management is not a feature or dashboard. It’s a disciplined, system-wide process that transforms security findings into resolved production risks. For most teams, this lifecycle is broken, and often in more than one place.
Step 1: Ingest and Normalize Security Findings
Security data is scattered across multiple detection surfaces, including SAST, DAST, container scanners, IaC linters, CSPMs, and more. Each speaks a different dialect, often with its naming conventions, severity scales, and data structures. Without normalization, duplication is inevitable.
For example, a single container vulnerability may appear in the image registry, runtime agent, and CI scanner. Without deduplication and correlation, this becomes three separate alerts, each generating its own Jira ticket. Worse, they might differ in severity, adding to the confusion.
Step 2: Map to Real-Time Asset Inventory
Security findings don’t matter unless you can trace them to the asset in question, and that asset must exist in the real world, not in a spreadsheet or weekly export from the CMDB. The rise of ephemeral compute (containers, serverless, short-lived VMs) means many “assets” don’t live long enough to be captured by static inventories.
Real-time discovery is essential. But discovery alone isn’t enough. Each asset must carry a business context: Is it in production? Who owns it? Which repo deployed it? What tier of service does it belong to? Without this metadata, security can’t distinguish between an exposure that threatens core APIs and one buried in an abandoned sandbox.
Step 3: Add Context and Prioritize
Traditional severity metrics, such as CVSS, lack operational context. Prioritization must integrate multiple dimensions:
- Exploitability (via EPSS or threat intel)
- Reachability (is it externally exposed?)
- Business impact (does the asset serve a critical function?)
- Blast radius (what would compromise enable?)
A CVSS 9.8 in an isolated container in a non-production namespace likely poses less risk than a 6.5 in a production-facing API reachable over the internet. Recent high-profile vulnerabilities, such as CVE-2024-6387 in OpenSSH, demonstrate how low-complexity exploits in exposed systems can pose significant real-world risk if not prioritized appropriately.
The Exposure Management Lifecycle: From Findings to Remediation
Step 4: Assign Ownership Automatically
Remediation only happens when someone is responsible. However, most organizations lack ownership built into their infrastructure. They rely on institutional memory, tribal knowledge, and manual lookups.
Automated ownership inference, based on repository metadata, Terraform tags, IAM associations, or Slack directory groups, can transform every finding into a task assigned to a known team. Just as identity lifecycle management tools help streamline access governance, exposure platforms must continuously align asset ownership with real-world responsibility.
Step 5: Route into Engineering Workflows
Security work must be integrated into engineering systems, including Jira, GitHub, Linear, and Slack. But pushing alerts into those systems isn’t enough. Remediation tickets must carry structured, actionable context: what the issue is, where it exists in infrastructure, why it matters, and how to fix it.
Dumping scanner output into Jira creates noise. Engineering ignores what it can’t trust or contextualize. Integrating structured findings into developer workflows, similar to how automated unit testing frameworks provide actionable feedback, helps security tickets become part of the regular delivery cycle rather than an external burden.
Step 6: Validate and Close the Loop
Most teams validate remediation only when a scanner re-detects the issue. That delay introduces risk. Instead, validation should pull from deployment signals:
- Has the container image been rebuilt and redeployed?
- Does the runtime agent confirm the removal of the vulnerable binary?
- Has the SBOM or package manifest changed in production?
Validation must be automated and immediate, not batched. Exposure management is incomplete until you can confirm, with evidence, that the risk has been removed from production.
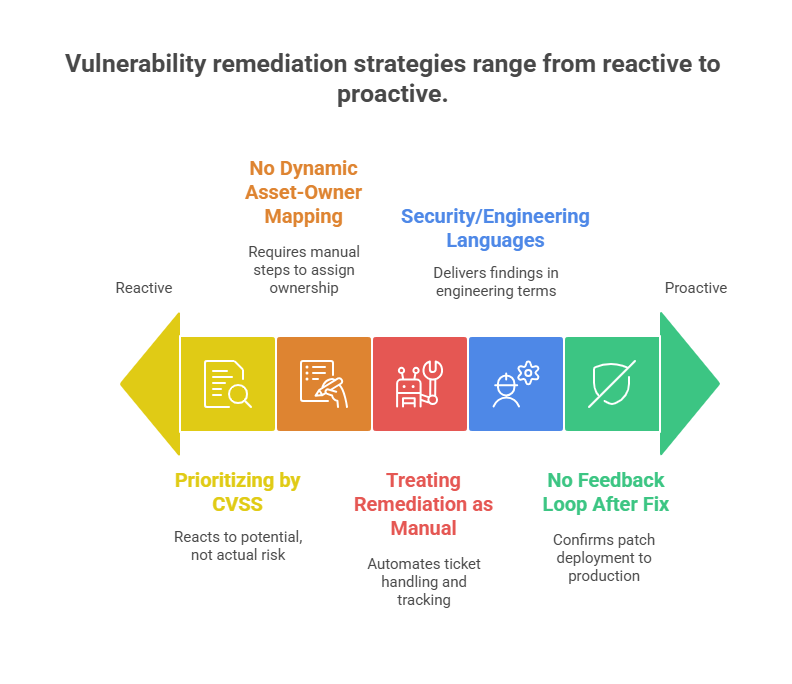
Vulnerability Remediation Maturity: From Reactive to Proactive
5 Common Pitfalls to Avoid
Most teams don’t struggle with exposure management because of bad scanners; they struggle because the system around those scanners is brittle. Here are five common pitfalls that sabotage remediation and let exposure linger long after it’s been “discovered.”
1. Prioritizing by CVSS Alone
Why it fails: CVSS tells you what could go wrong, not what’s likely to. It ignores whether a vulnerability is internet-facing, in production, or actively exploited in the wild.
What to do instead: Shift to a risk-based model that includes exploitability (EPSS), reachability, asset criticality, and blast radius. A CVSS 5 on a public S3 bucket should rank higher than a 9.8 in an isolated dev container. Prioritize what attackers can reach.
2. No Dynamic Asset-Owner Mapping
Why it fails: If a vulnerability can’t be traced to a specific team, it won’t get fixed. Manual owner lookups waste time, introduce errors, and stall triage.
What to do instead: Ownership should be inferred from cloud tags, repo metadata, and deployment relationships, automatically and continuously. Tribal knowledge isn’t scalable.
3. Treating Remediation as a Manual, One-Off Task
Why it fails: Manually filed tickets get lost, duplicated, or ignored. Fixes aren’t tracked. Deadlines drift. Risk lingers in prod.
What to do instead: Embed remediation in the same systems where engineering already works. Ticket creation, routing, tracking, and closure should be part of a continuous, automated workflow. This shift addresses many of the common vulnerability remediation challenges teams face, from coordination delays to a lack of accountability.
4. Security and Engineering Speak Different Languages
Why it fails: Engineers often ignore tickets that appear to be raw scanner exports. Security sees this as apathy. It’s a breakdown in trust and communication.
What to do instead: Deliver contextual findings that map to services and repos, explain risk in engineering terms, and include remediation steps developers can act on.
5. No Feedback Loop After Fix
Why it fails: Teams close tickets once code merges, but that doesn’t mean the patch made it to production. Risk often lingers due to missed deployments or rollbacks.
What to do instead: Confirm closure with signals like container digests, runtime logs, or SBOM diffs. Don’t assume remediation. Validate it.
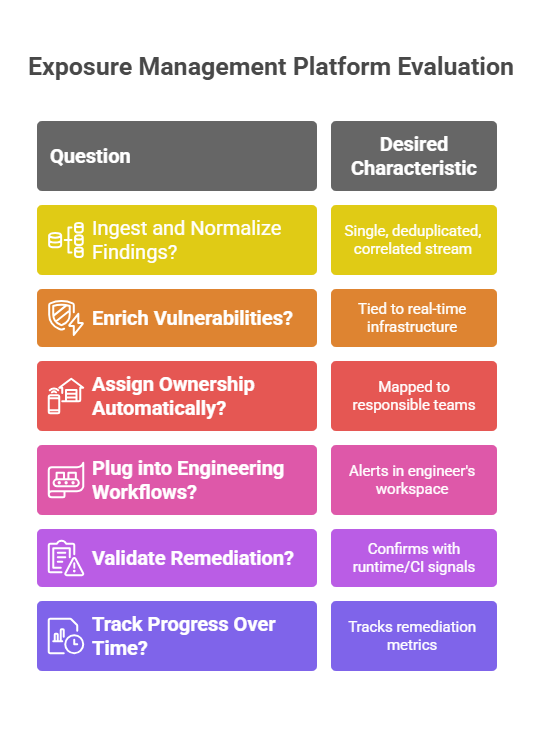
Key Capabilities to Evaluate in an Exposure Management Platform
6 Questions to Ask An Exposure Management Platform
Teams need a system that translates detection into action. If you’re evaluating exposure management platforms, focus less on feature lists and more on whether the system drives resolution. Choosing the right unified vulnerability management and remediation platform is crucial for closing the loop between detection and validation of fixes. Here are the questions to ask and what to look out for.
1. Does it ingest and normalize findings across scanners?
Your platform should consolidate SAST, DAST, CSPM, container, and IaC findings into a single stream, deduplicated and correlated across tools.
2. Does it enrich vulnerabilities with asset metadata and business context?
Findings should be tied to real-time infrastructure with tags like environment (prod/staging), service name, and risk tier. Static CMDBs don’t cut it.
3. Can it assign ownership automatically based on asset tags, repo ownership, or org chart?
Manual owner assignment slows everything down. The platform should automatically map issues to the responsible teams without requiring human intervention.
4. Does it plug into engineering workflows (e.g., Jira, GitHub, Slack)?
Alerts should land where engineers already work—enriched, scoped, and in their language, not in a security-owned silo.
5. Can it validate remediation and close tickets automatically?
Once a fix is deployed, the system should confirm with runtime or CI signals, such as container digests, SBOM updates, or deployment logs, rather than waiting for the following scan.
6. Does it track progress over time (TTM, exposure backlog, % resolved)?
You can’t manage what you don’t measure. Look for a platform that tracks remediation metrics in terms of actual risk reduction.
Stop Triage Theater and Start Reducing Risk.
Security teams don’t need another place to look at vulnerabilities. They need a system that routes real risk to the people who can fix it and confirms when they do. That means fewer alerts, fewer dead tickets, and no more guessing whether the fix has been implemented in production.
Exposure management is a loop: normalize findings, scope them to real infrastructure, map them to owners, push them into engineering workflows, and close the loop with fix validation. Most teams fake this with brittle scripts and backlogs that never shrink.
But it doesn’t have to be this way. DevOcean gives you the system your team has been duct-taping together, and one that makes exposure someone’s responsibility and ensures it gets resolved. If you’re ready to operationalize exposure management instead of managing around it, try a demo, and we’ll show you how DevOcean makes it accountable, automated, and scalable.
%20Breach.png)
.png)

The true cost of poor security remediation.
Goes beyond wasted resources, overspent budgets, and missed SLAs.
Stay ahead of breaches - get started with DevOcean.